

When you are dealing with large amounts of data, accomplishing tasks using the data becomes a tedious task. Your work is decreased significantly if your data is properly sorted. That’s exactly the job for the sort command.
The sort command in Linux, as the name suggests, is used to sort the contents of a text file in the specified order. It works only for text files. When the sort command receives a file, it assumes the content to be in ASCII format by default.
What’s the sort Command used For?
In general, the sort command is used to sort the input data alphabetically or numerically in an ascending or descending order. This is very simple to use command and there really isn’t much “meat” to it compared to the other commands that we’ve worked on before. But it’s a very handy utility. Let’s have a look at the syntax and understand some basics of the sort command.
Understanding the sort command in Linux
The sort command is one of the simplest, yet one of the most useful commands available to you. The syntax of this command looks like this:
sort [options] FileName.txt
The ‘options’ are responsible to dictate the rules based on which the file (here FileName.txt) is sorted. If no options are mentioned, the sort command in Linux sorts the file using its default rules. The default rules of the sort command are:
- Sorting the text in ascending alphabetical order
- Letters are placed below numbers in the sorted list
- A lowercase letter is placed higher than its uppercase counterpart
Command Options for the sort command in Linux
The sort command in Linux provides us with a variety of options to customize how we sort our text files. These are some of the options listed below, along with their effect on the sort command.
- -n: Sort data based on the
- -R: Display the values in a random order
- -r: Sort data in a descending order
- -k: Used when the data is divided into multiple columns
- -u: Sort and display unique values only
- -o: Save the output in a different file
- -c: Check if the specified file is sorted or not
Play around with these options as they can be combined with each other to get specific results.
Using the sort command in Linux
Let’s look into the usage of the sort command and understand how to use the different options that are available for it.
Sorting the file alphabetically
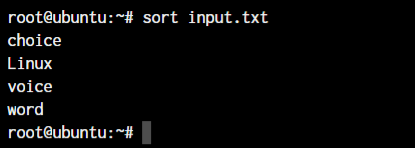
The most basic use of the sort command is to sort the contents of a file in alphabetical order. As this is covered by the default rules of the sort command, we don’t need to use any option for this operation on a text file. For this demonstration, we’ll create a file named input.txt and add a few random words in it.
word
choice
voice
Linux
To sort this file in the alphabetical order, we use the following command:
sort input.txt
Sort Numbers with the sort command in Linux
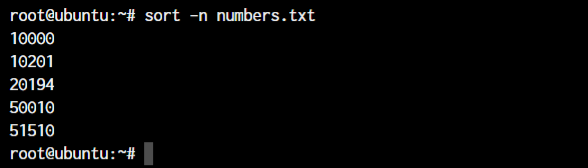
The sort command in Linux by default doesn’t compare the numbers to check a specific number is greater than another. It simply checks the first digit of any number is greater than or smaller than the next.
51510
10000
20194
10201
50010
Sort in Descending Order using the sort Command in Linux
Consider our input.txt file again with the exact same content as above. The reverse sort command in Linux will sort the contents of the file in the descending order.
sort -r input.txt
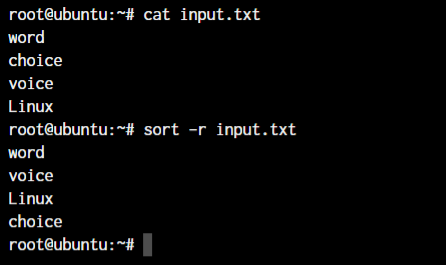
As you can see in the above example, the output is now sorted in the descending order.
Sorting the file in a randomized order (-R)
The use case for this specific option will be more within shell scripts to randomly pick up information from files. Let’s randomly sort our input.txt file.
sort -R input.txt
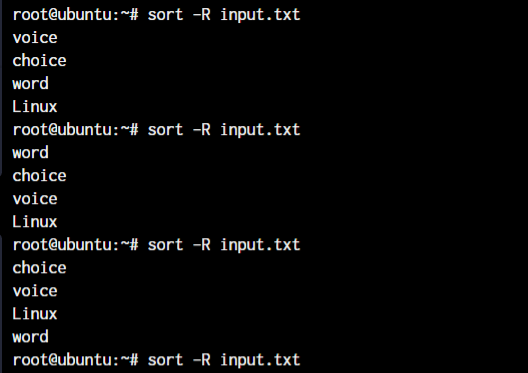
As you can see, all the command results show a different sorting order.
Sorting the file by column
Let’s create a file with two columns. Columns are simply separations between two words that are common in all the lines. In the below example, I’m separating two strings by a space and have kept that same pattern common among the entire set of data.
100 Drinks
40 Snacks
250 Meal
80 Dessert
Let’s sort this data by column one and column two.
sort -k <column number> <file or text data>
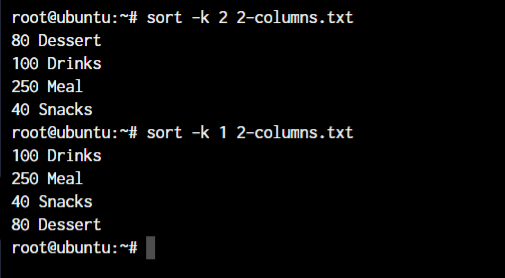
Notice how the first output is sorted by the “First letter” of the second column while the second output is sorted by “First number” of the first column.
The sort command doesn’t really understand the fact that the number 100 is greater than the number 40. It only checks for the first digit. What if we combine the -n option with the above existing command?
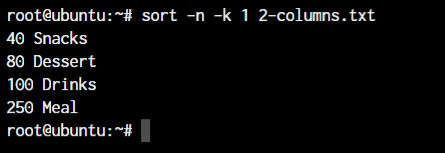
That’s exactly what we want! Awesome.
Sort and Output Only Unique Values
If you have a file that consists of a lot of duplicate values and you simply need to get a sorted list of all the unique values, this is the command that you need to use. Let’s create a file with some duplicate values:
one
one
two
three
four
four
Let’s run the sort command with the -u option.
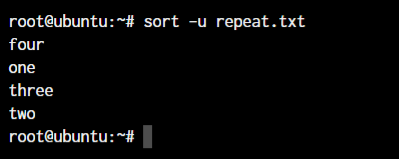
Sorting the file and directing the output to a file
As you may have noticed that the sort command does not change the file contents but only displays the updated output on the terminal. So how can we save the output to a file? We can use the output redirect operator > or use the -o option here.
For this demonstration, let’s go back to our file input.txt. To sort this file and send it to another file output.txt, we use the following command:
sort -o <output file> <input file or text data>
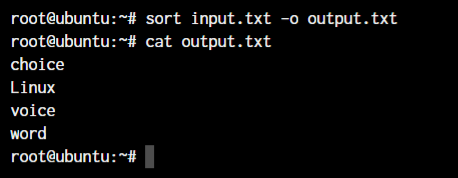
Check if a Set of Data is Already Sorted
If you want to check if a large file of numbers or words is already in sorted order or not, you can use the -c option.
sort -c <filename>
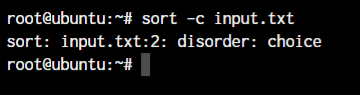
As you can see, the sorted order is displayed as “Disorder:” followed by the word that’s not in order. If the file is correctly sorted, there will be no output.
Conclusion
This brings us to the end of the tutorial for the sort command in Linux. We’ve covered some of the common methods to sort data here but you can explore the sort command in Linux using the man command to view the detailed manual pages.