

Sed command is a text editor tool used for editing files, which is command line-based. But what sed is really used for is something called ‘Steam Editing.’ Also! ‘S’ in Sed stands for Stream-oriented, and the ‘ed’ part is for the editor.
And now, you are wondering what stream editing is.
What is Stream Editing?
Stream editing is modifying a stream of text data that could be generated by any program or Operating System itself in real-time as it is being read from an input source or before it is written to an output destination. Stream editing is commonly used for tasks such as search-and-replace operations, text transformations, and data manipulation.
Also, check out the other command line-based text editors in Linux.
How Does ‘sed’ Help in Stream Editing?
It reads text data from an input source (such as a file or standard input), edits the text according to a set of editing commands, and then sends the edited text to an output destination (such as standard output or a file). Because data is processed continuously with sed, it is possible for it to be much quicker and more efficient than other text editors, which load the entirety of the file into memory before making any modifications.
Stream editing is a handy technique when dealing with enormous volumes of data since it may process the data one line at a time rather than putting the full file into memory. This allows the data to be processed more quickly. Because of this, it is now feasible to carry out complicated transformations on extremely huge files without running out of memory.
Here Are Some Common Examples of Stream Data in Linux
In Linux, stream data refers to a continuous flow of text-based data that can be processed in real-time. Some common examples of stream data in Linux include:
Standard Input (stdin): Keyboard input that is entered into the command line can be considered a stream of data. This data can be passed as input to a command or program through the use of the standard input stream (stdin).
Standard Output (stdout): The output generated by a command or program can be considered a stream of data. This data can be redirected to a file or displayed on the screen through the use of the standard output stream (stdout).
Pipes: Pipes are a way to connect two or more commands, allowing the output of one command to be used as the input for another. The data that flows through a pipe can be considered a stream of data.
Files: Files can be considered streams of data, as they contain a continuous flow of text-based information.
Network Data: Data transmitted over a network connection can be considered a stream of data.
Syntax of ‘sed’
sed [options] 'command or script' inputfile(s)
Where:
options: optional flags that control the behavior ofsed. Some standard options include-nsuppressing the default printing of all lines, -i to edit files in place, and -e specifying multiple commands.commandor script: The text processing command to be executed bysed. This can be a simple search and replace operation or a more complex transformation using regular expressions.inputfile(s): The name of the input file(s) to be processed bysed. If no input file is specified,sedwill process input from standard input.
One important thing to note while working with sed is that the original input file is unchanged, and the results are sent to standard output. The redirection operator (>) has to be used to redirect the output to a file. To make changes to the original file (not recommended) “-i” flag can be used.
The sed command has two parts: an address and a command. The address specifies the location where the change is to be made. An address can be a line number, a string literal, or even a regular expression. The command part is used to differentiate between the various actions, such as insert, delete, and substitute.
Example of Sed Command Replacing Occurrences of a Particular Word
Here’s an example that replaces all occurrences of the word “apple” with the word “banana” in a file named fruits.txt:
sed 's/apple/banana/g' fruits.txt
In this example, s/apple/banana/g is the sed command that performs the search and replace operation. The g flag at the end of the command specifies that the replacement should be performed globally, meaning that all occurrences of “apple” in each line should be replaced. The output of the command is sent to standard output, which can be redirected to another file if desired.
The Flags And Arguments of sed
‘sed’ has several flags and arguments that can be used to control its behavior:
-n: Suppresses the default behavior ofsed, which is to print all lines to standard output. When-nis used,sedwill only print lines that have been explicitly specified using thepcommand.-i: Edits the input file(s) in place, meaning that the changes made bysedare saved back to the original file. Without the-iflag,sedoutputs the changes to standard output.-e: Specifies multiple commands to be executed bysed. This flag is used to apply multiple transformations to a single file or to apply different transformations to different files.-f: Specifies a file that contains a list ofsedcommands to be executed. This is useful for complex or repetitive operations that can be stored in a file for reuse.address: Specifies the range of lines that asedcommand should be applied to. The address can be a line number, a regular expression, or a range of lines (e.g.,1,10).s/old/new/flags: Thes(substitute) command is used to search for a pattern (old) and replace it with a new string (new). Theflagsargument is optional and can be used to control the behavior of the substitution, such as making it global (g), or case-insensitive (I).d: Thed(delete) command is used to delete lines that match a specific address or pattern.p: Thep(print) command is used to print the lines that match a specific address or pattern. When used with the-nflag,pis used to explicitly specify which lines should be printed bysed.a: Thea(append) command is used to add text to the end of a line.i: Thei(insert) command is used to insert text before a line.c: Thec(change) command is used to replace a range of lines with new text.
These are the main flags and arguments that are commonly used with the sed command. The exact syntax and behavior of each argument can vary depending on the version of sed that you are using.
Creating a file for editing
First off, we will start by creating a file that will be used throughout this tutorial to apply the transformations.
$ cat > output.txt
The text we are going to use is :
Apples are sweet in taste.
Apples are red in colour. Orange is sweet too.
Orange is Orange in colour. Colour of a fruit can’t be changed.
Apples and oranges are healthy. Orange needs to be pealed while an apple can be consumed without pealing.
Apples are sometimes green in colour. An orange if green in colour is not ripe enough to eat.
Apples and oranges grow on trees. More people like to eat apples.
That's about it for apples and oranges.
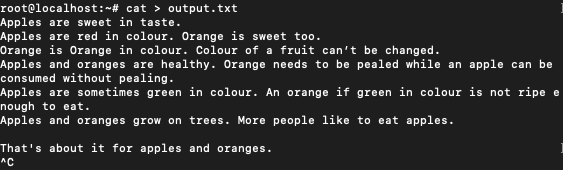
Note the multiple occurrences of words like apples and oranges.
Following Are Various Examples And Demonstrations Exploring the Usage of ‘sed’
Replacing words
The sed command can be used to find occurrences of particular words across the text and replace it. This can be useful if the spelling of a word is wrong and needs to be corrected.
$ sed 's/colour/color/' output.txt
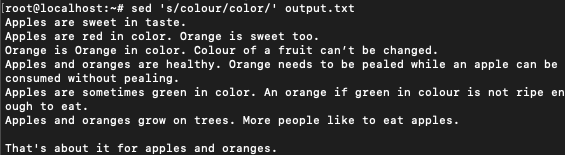
This command only replaces the first occurrence of the target word in each line. If you notice that in the third line we have ‘Colour’ which is still not replaced. This is because of two reasons:
- The command we wrote doesn’t ignore the case of the words. That is to say, it is case-sensitive.
- Even if it ignored the case, it will still not replace the second instance of a word in a line.
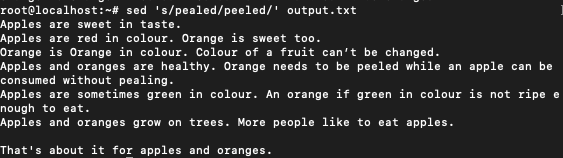
If you notice words ‘pealed’ and ‘pealing’ are wrongly spelled. We can correct them individually
$ sed 's/pealed/peeled/' output.txt
$ sed 's/pealing/peeling/' output.txt
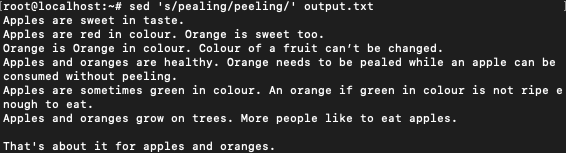
In changing them individually, we see that the other returns to the original version. Later we will see how Regular Expressions can be used to achieve the same result.
Replacing multiple words
In the previous example, instead of using the sed command twice we can use a single command combining the two.
$ sed -i 's/pealed/peeled/;s/pealing/peeling/' output.txt
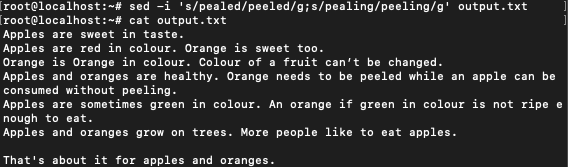
This command takes care of both the substitutions simultaneously. Here we use “-i” to make the change in the original file. This is why we have to run a cat command to see the original file. Don’t confuse this “-i” with the one that is used for making case-insensitive substitutions(see next example).
Ignore case while replacing
sed by default is case sensitive. To ignore the case -i flag can be used with sed command.
$ sed 's/apples/mango/i' output.txt
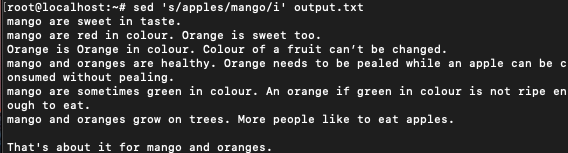
All the first instances of the world apples have been changed to mango irrespective of the case. You can see that in second last line we still have ‘apples’ as it is. Being the second instance of the word in the same line it has not been replaced.
Replacing all occurrences
As we saw above, the command we have been using so far only looks at the first occurrence in each line. To look at all instances of a word use -g along with the command. Let’s have another look at that second instance of ‘Colour’ in line 3.
$ sed 's/colour/color/gi' output.txt
- g makes sure that all instances are looked at
- i makes sure that matching is case-insensitive
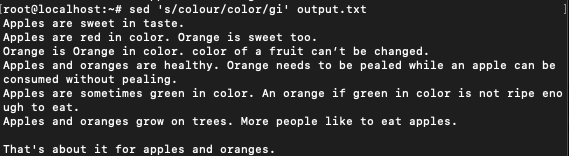
Nice! both the instances of the word colour have been changed to color in line 3.
Replacing selective occurrence
Now suppose we just want to change the second occurrence of a word in each line. This would mean to only change the second occurrence of ‘colour’ in line 3.
$ sed 's/colour/color/2i' output.txt
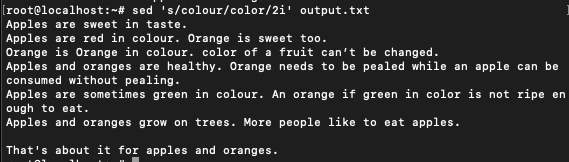
In the output, the only occurrence of colour in line #2 and the first occurrence in line #3 is left as it is. The second occurrence in line #3 has been replaced by ‘color’. The same is true for the third last line. By replacing g with any n, we can use sed to replace the nth occurrence of a word in each line.
Adding a line after every line
Sometimes it is nice to space out each line in the file. This can be done using ‘G’ with sed command.
$ sed G output.txt
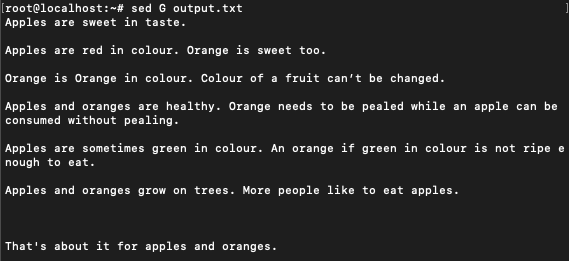
As we can see, a line has been added after every line of text.
Replacing words in selective lines
We can mention specific lines to run the sed editor tool on. This would only make the changes in the lines mentioned explicitly and ignore the rest.
$ sed '2,4 s/Apples/mango/' output.txt
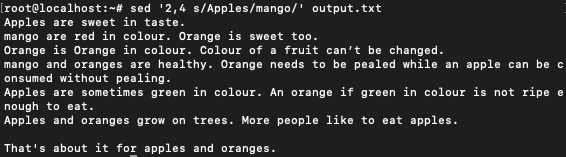
We can see that only lines 2 to 4 have been modified. Since we didn’t mention g, only the first occurrences have been modified.
Printing selected lines
The sed command can be used to display particular lines from the file.
$ sed -n '2,5p' output.txt

Deleting selected lines
The sed command can be used to remove certain lines while displaying. The command doesn’t delete the lines from the actual file, rather it just doesn’t display them when the command is run.
$ sed '2,5d' output.txt

This won’t affect the original file, so think of it as another way of selectively displaying a file. To save the output to another file we can use the redirection operator. We’ll see this next.
Saving sed output to a file
The modifications made through sed command is only visible as an output on the command line. These outputs are not saved and the changes are not reflected in the original file. To save the changes to a file, redirection operator (>) can be used.
$ sed '2,5d' output.txt > new_file.txt

Note that if new_file.txt doesn’t exist, this command will create the file then write the output to it. The file would be created in the current working directory.
Displaying multiple consecutive lines
Just like performing multiple substitutions in the same command, sed can be used to display multiple consecutive lines in a single command.
$ sed -n -e '2,3p' -e '5,6p' output.txt

Lines 2 through 3 and lines 5 through 6 are displayed.
Printing lines that contain a particular word
The sed command can be used to print lines that contain a certain word or a pattern.
$ sed -n /colour/p output.txt
This command prints all the lines with ‘colour’ word in it.
$ sed -n /Colour/p output.txt

Since we haven’t used -i with sed command, the two commands will give different outputs.
Using Regular Expressions
The sed command can be used along with regular expressions to search for patterns. Regular expressions are used to specify certain rules that can be used to match the text and look for patterns.
$ sed ’s/[Cc]olour/color/g’output.txt
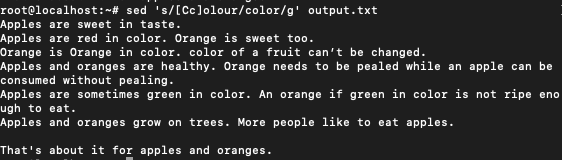
This solves the problem of matching Colour and colour as we have specified a regex for [Cc]olour which matches both the occurrences.
Advanced RegEx substitution
Earlier we saw how we replaced pealed to peeled and pealing to peeling. Let’s try doing that by regular expression. We will create one regular expression that will change peal to peel and rest of the the word as it is. This can be useful if the same word is used in many forms such as past, present or future.
sed 's/peal\([a-z]*\)\(\.*[[:space:]]\)/peel\1\2/g' output.txt
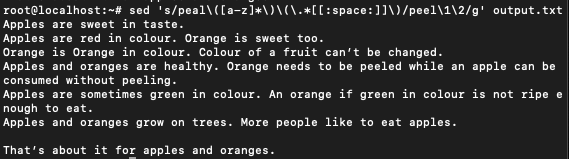
The regular expression identifies both pealed and pealing and corrects them. Let’s understand the regular expression.
Backslash are used to escape characters like parenthesis, without which the expression would look like:
peal([a-z*])(.*[[:space:]])
- Peal matches the first four letters of the word.
- [a-z]* matches zero or more alphabets after peal. This would be used for matching ‘ed’ and ‘ing’
- .* matches zero or more number of dots, used as full-stop. Used for pealing since it occurs at the end.
- [[:space:]] matches the space after a word. Used for pealed.
- ([a-z]) is referenced as 1 and can be used while substitution back.
- (.*[[:space:]]) is referenced as 2.
On the substituting side we have :
peel\1\2
Backslash is used to escape numeric characters. Here peel is followed by the reference 1 from the matched patter which is either ‘ed’ or ‘ing’. Followed by 2 which is either a space or a full-stop. This regular expression successfully achieves the following transformation:
- pealing. -> peeling.
- pealed[space] -> peeled[space]
Does ‘sed’ Command Come Pre-Installed in our Operating System?
Yes, the sed command typically comes pre-installed on most Unix-based operating systems, including Linux and macOS. This means that you can use sed out of the box without having to install any additional software. If you are using a Windows operating system, you may need to install a Unix-like environment such as Cygwin or WSL (Windows Subsystem for Linux) in order to use sed
Is sed useful?
Yes, sed is a useful tool for real-time processing and modification of text-based data in Linux. It is efficient for tasks such as search-and-replace operations, text transformations, and data manipulation. sed can handle large data sets and is a valuable tool for system administrators, programmers, and data analysts.
What is the difference between sed and grep?
sed and grep are both Linux commands, but they serve different purposes. grep is used for searching and filtering text-based data, while sed is used for editing and transforming text-based data in real-time. grep outputs the matching lines, while sed outputs the modified data.
Is sed faster than grep
The speed of sed and grep depends on the task being performed and the size of the data being processed. For simple search and filtering tasks, grep may be faster. However, for complex editing tasks, sed can be faster as it processes data in a continuous stream, allowing for real-time transformations.
Conclusion
We had a fun time exploring the applications of sed here at Linuxfordevices. The sed command along with regular expressions can be used for very powerful text editing. Study more about regular expressions here. We only covered the brief applicability of sed command. To know more about sed refer to this.