

The awk command is fundamentally a scripting language and a powerful text manipulation tool in Linux. It is named after its founders Alfred Aho, Peter Weinberger, and Brian Kernighan. Awk is popular because of its ability to process text (strings) as easily as numbers.
It scans a sequence of input lines, or records, one by one, searching for lines that match the pattern. When a match is found, an action can be performed. It is a pattern-action language.
Input to awk can come from files, redirection and pipes or directly from standard input.
Terminology
Let’s get on to some basic terms before we dive into the tutorial. This will make it easier for you to understand the concept better.
1. Records
awk perceives each line as a record.
- RS is used to mention record separators. By default, RS is set to newline.
- NR is the variable that tracks the record number. Its value is equal to the record being processed. NR can be assumed to be the line number in the default scenario.
2. Fields
Each record is split into fields. That means each line is broken into fields.
- FS is the field separator. By default FS is set to whitespace. That means each word is a field.
- NF is the Number of Fields in a particular record.
Fields are numbered as:
- $0 for the whole line.
- $1 for the first field.
- $2 for the second field.
- $n for the nth field.
- $NF for the last field.
- $NF-1 for the second last field.
Standard format of awk
The standard format of awk command is:
$ awk ' BIGIN{/instructions/} /pattern/ {ACTIONS} END{/instructions}' file_name
- The pattern-action pair is to be enclosed within a single quote(‘)
- BEGIN and END is optional and is used for mentioning actions to be performed before and after processing the input.
- The pattern represents the condition that if fulfilled leads to execution of the action
- The action specifies the precise set of commands to be performed when there is a successful match.
- file_name is to be specified if the input is coming from a file.
Basic usage of the awk command
awk can be used to print a message to the terminal based on some pattern in the text. If you run awk command without any pattern and just a single print command, awk prints the message every time you hit enter. This happens because awk command is expecting input from the command line interface.
$ awk '{print "This is how awk command is used for printing"}'

Processing input from the command line using awk
We saw in the previous example that if no input-source is mentioned then awk simply takes input from the command line.
Input under awk is seen as a collection of records and each record is further a collection of fields. We can use this to process input in real-time.
$ awk '$3=="linux" {print "That is amazing!", $1}'

This code looks for the pattern where the third word in the line is ‘linux”. When a match is found it prints the message. Here we have referenced the first field from the same line. Before moving forward, let’s create a text file for use as input.
This can be done using cat command in linux.
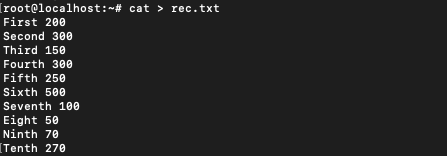
The text of the file is:
First 200
Second 300
Third 150
Fourth 300
Fifth 250
Sixth 500
Seventh 100
Eight 50
Ninth 70
Tenth 270
These could be the dues in rupees for different customers named First, Second…so on.
Printing from a file using fields
Input from a file can be printed using awk. We can refer to different fields to print the output in a fancy manner.
$ awk '{print $1, "owes", $2}' rec.txt
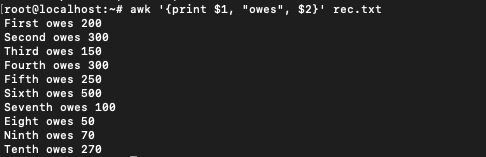
$1 and $2 are used for referring to fields one and two respectively. These in our input file are the first and second words in each line. We haven’t mentioned any pattern in this command therefore awk command runs the action on every record. The default pattern for awk is “” which matches every line.
Playing with awk separators
There are three types of separators in awk.
- OFS: output field separator
- FS: field separator
- RS: record separator
1. Output field separator (OFS)
You can notice that by default print command separates the output fields by a whitespace. This can be changed by changing OFS.
$ awk 'OFS=" owes " {print $1,$2}' rec.txt
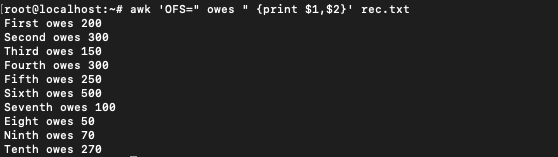
The same output is achieved as the previous case. The default output field separator has been changed from whitespace to ” owes “. This, however, is not the best way to change the OFS. All the separators should be changed in the BEGIN section of the awk command.
2. Field Separator (FS)
Field separator can be changed by changing the value of FS. By default, FS is set to whitespace. We created another file with the follow data. Here the name and the amount are separated by ‘-‘
First-200
Second-300
Third-150
Fourth-300
Fifth-250
Sixth-500
Seventh-100
Eight-50
Ninth-70
Tenth-270
$ awk 'FS="-" {print $1}' rec-sep.txt
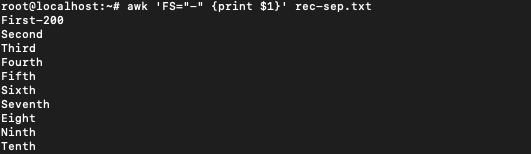
You can notice that the first line of the output is wrong. It seems that for the first record awk was not able to separate the fields. This is because we have mentioned the statement that changes the field separator in the action section. The first time action section runs, is after the first record has been processed. In this case, First-200 is read and processed with field separator as whitespace.
Correct way:
$ awk 'BEGIN {FS="-"} {print $1}' rec_1.txt
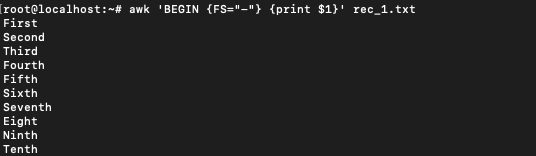
Now we get the correct output. The first record has been separated successfully. Any statement placed in the BEGIN section runs before processing the input. BEGIN section is most often used to print a message before the processing of input.
3. Record separator (RS)
The third type of separator is record separator. By default record separator is set to newline. Record separator can be changed by changing the value of RS. Changing RS is useful in case the input is a CSV (comma-separated value) file.
For example if the input is:
First-200,Second-300,Third-150,Fourth-300,Fifth-250,Sixth-500,Seventh-100,Eight-50,Ninth-70,Tenth-270
This is the same input as above but in a comma separated format.
We can process such a file by changing the RS field.
$ awk 'BEGIN {FS="-"; RS=","; OFS=" owes Rs. "} {print $1,$2}' rec_2.txt
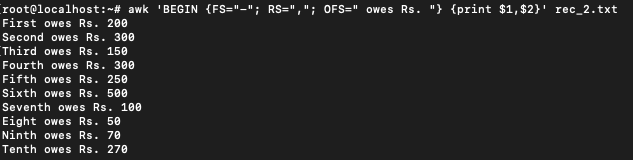
Boolean operations in awk
Boolean operations can be used as patterns. Different field values can be used to carry out comparisons. awk works like an if-then command. In our data, we can find customers with more than Rs. 200 due.
$ awk '$2>200 {print $1, "owes Rs.",$2}' rec.txt

This gives us the list by comparing the second field of each record with the 200 and printing if the condition is true.
Matching string literals using the awk command
Since awk works with fields we can use this to our benefit. Running ls -l command gives the list of all the files in the current directory with additional information.
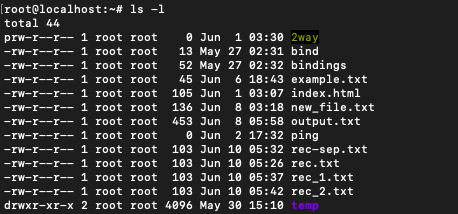
The awk command can be used along with ls -l to find out which files were created in the month of May. $6 is the field for displaying the month in which the file was created. We can use this and match the field with string ‘May’.
$ ls -l | awk '$6=="May" {print $9}'

User-defined variables in awk
To perform additional operations variables can be defined in awk. For example to calculate the sum in the list of people with dues greater than 200 we can define a sum variable to calculate the sum.
$ awk 'BEGIN {sum=0} $2>200 {sum=sum+$2; print $1} END{print sum}' rec.txt

The sum variable is initialized in the BEGIN section, updated in the action section, and printed in the END section. The action section would be used only if the condition mentioned in the pattern section is true. Since the pattern is checked for each line, the structure works as a loop with an update being performed each time the condition is met.
Counting with the awk command
The awk command can also be used to count the number of lines, the number of words, and even the number of characters. Let’s start with counting the number of lines with the awk command.
Count the number of lines
The number of lines can be printed by printing out the NR variable in the END section. NR is used to store the current record number. Since the END section is accessed after all the records are processed, NR in the END section would contain the total number of records.
$ awk 'END { print NR }' rec.txt

Count number of words
To get the number of words, NF can be used. NF is the number of fields in each record. If NF is totalled over all the records, the number of words can be achieved. In the command, c is used to count the number of words. For each line, the total number of fields in that line is added to c. In the END section, printing c would give the total number of words.
$ awk 'BEGIN {c=0} {c=c+NF} END{print c}' rec.txt
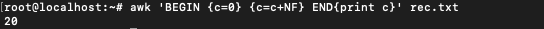
Count number of characters
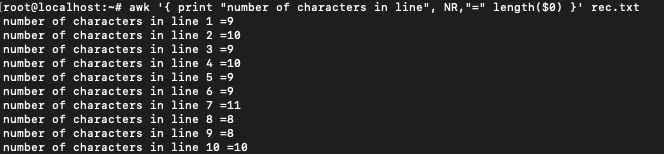
Number of characters for each line can be obtained by using the in built length function of awk. $0 is used for getting the entire record. length($0) would give the number of characters in that record.
awk '{ print "number of characters in line", NR,"=" length($0) }' rec.txt
Conclusion
awk command can be used for performing very powerful text manipulations. The convenience of directly accessing fields gives awk a major advantage over sed. As mentioned, awk is not just a command-line tool but also a powerful scripting language. To learn more about awk refer this.