

In this tutorial, we are going to discuss curl command in Linux. Basically, the curl command is used to access and download files on a remote server. Since even HTML documents are files, the curl command can extract entire web pages and save them on your local disk. Let’s find out how to use the command and understand the command in a little more detail.
What is the curl command in Linux?
The curl command is used to transfer data from any server over to your computer. If you don’t have the curl command installed in your system, you can download it using your package manager:
#Debian and Ubuntu Systems
sudo apt install curl
# Red hat, CentOS, Fedora
sudo rpm install curl
sudo yum install curl
sudo dnf install curl
#OpenSUSE
sudo zypper install curl
#Arch Linux
pacman -S curl
The syntax for the curl command is as follows:
# curl http://[ip address]/[filename]
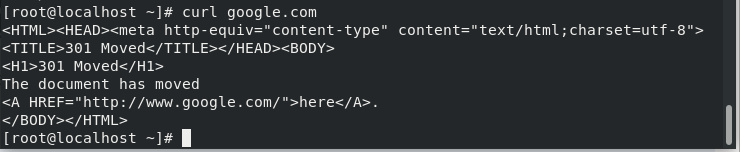
Let’s discuss more the options used with the curl command.
- -I: to get the HTTP headers
- –-cookie: to fetch the cookies and store it in a file
- -L: to follow redirects
- –limit-rate: to specify the transfer rate
- -O: to save the output to a file
Extract HTTP Headers Using the curl Command in Linux
Basically, HTTP headers are colon-separated key-value pairs containing information such as date, content-type, connection, set-cookies and so on. Headers are wrapped with the request and response services between client and server. ‘-I’ is used to get the HTTP headers.
The syntax for the following is as follows:
# curl -I [URL]
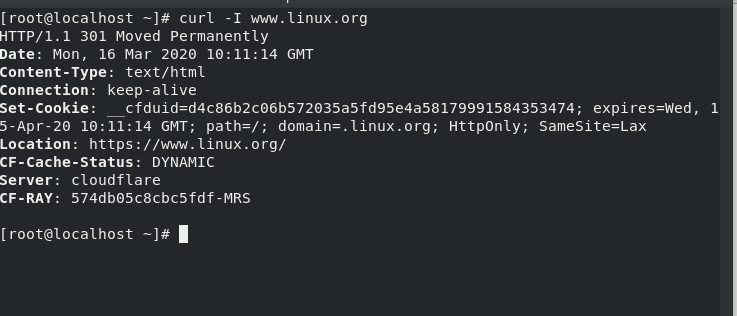
This command will display the headers of the site.
Store cookies using the curl command in Linux
Cookies are used to identify users or we can say it is a small amount of data generated by the website. Curl command also provides you the option to save the cookies.
The syntax for the following is :
# curl --cookie [filename] [siteURL]
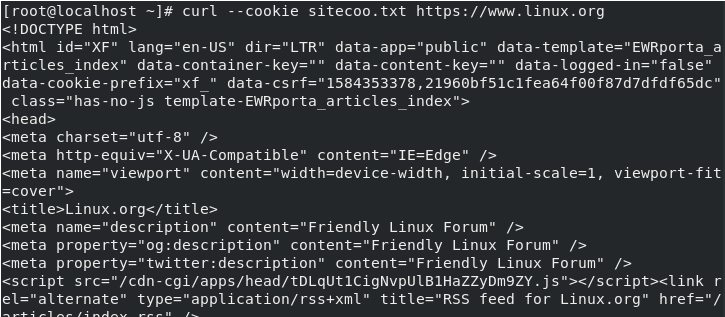
Here, the cookies will get stored in a file fetched from a site.
Check whether URL supports HTTP/2
As discussed earlier, -I is used to fetch HTTP headers. Now, what if, you want to check whether it supports HTTP/2 protocol. HTTP/2 is the revised version of HTTP used in networking. For this, we will use ‘-I’ along with ‘--http2‘ option. The -s in the command below is for silencing progress related output.
The syntax for the following is:
# curl -I --http2 -s [siteURL] | grep HTTP

Here, ‘-s’ lets the curl command run silently or hiding the error messages.
Follow Redirects Using the curl Command in Linux
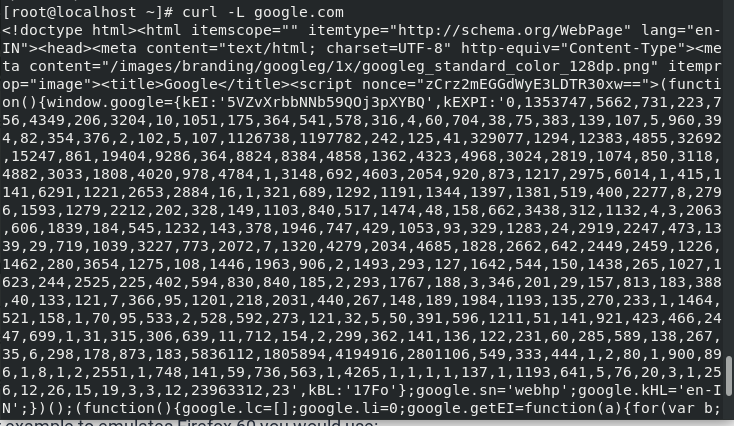
Curl command doesn’t follow the HTTP headers. If you want to retrieve the google.com, so instead of printing its source code it will print the following result.
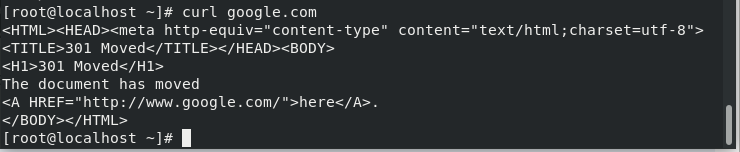
So basically, to follow the redirects until it reaches any final destination we use the ‘-L’ option as shown below.
The syntax for the following is :
# curl -L google.com
Redirect curl command output to a file using the “>” operator
We’ve seen this operator quite often in our previous tutorials. This operator is called the redirect operator and allows us to send the output from a particular command straight to a file that we specify. In this case, we use the curl command in Linux to download the “linux.org” homepage and store it into a file
The syntax for the following is:
# curl [siteurl] > [filename]

Here, it will store the fetched output to linux.html file.
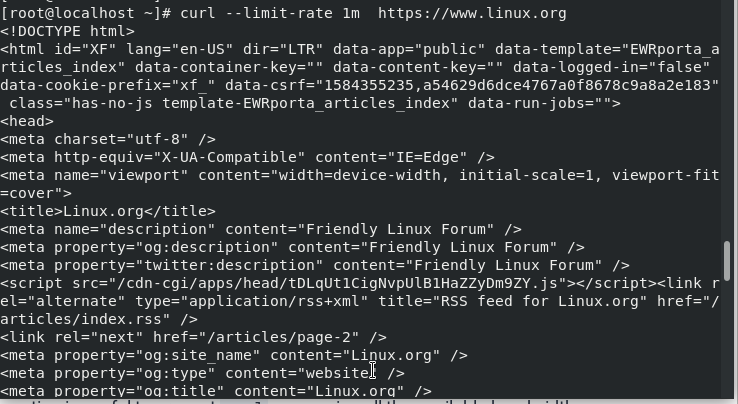
To specify the transfer rate using curl command in Linux
The curl option also provides the option to limit the data transfer rate. The values can be described in bytes, kilobytes, megabytes or gigabytes having the suffix k,m, or g respectively. ‘–limit-rate’ option is used to specify the transfer rate.
The syntax for the following is :
# curl --limit-rate 1m [siteurl]
Download and Save a File Without Renaming
The -O command option allows the file to be downloaded and saved without renaming it. If you want an option to rename the file before it’s downloaded and saved, you can use the -o option which is lowercase letter O, and specify the filename.
The syntax for downloading a file is :
# curl -O [site URL]

It will download the content of the file and will save it in a file with its original name.
Know the Version
We will use the ‘–version’ option with the curl command in Linux to output the version.
The syntax for the following is :
# curl --version
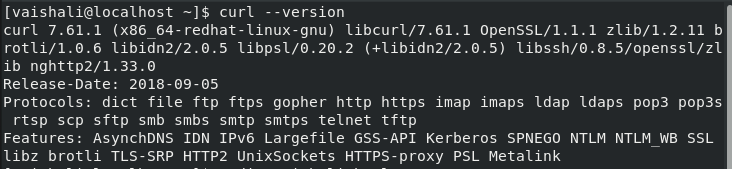
It will print the version of the curl command.
Conclusion
In this tutorial, we’ve gone through how to use the curl command in Linux. We hope that you now know how to use the command efficiently. If you have any questions, do let us know in the comments.