

In this tutorial, we are going to discuss a very interesting and informative topic that is a Defunct or Zombie Process in Linux. We will also discuss the init process, SIGCHLD signal, system calls [fork(), exit(), & wait()], and Linux commands [ps, top, & kill].
What is a Zombie Process in Linux?
In Linux, a Zombie Process is a process that has completed its execution and got terminated using the exit() system call but still, it has its entry in the system’s process table. A Zombie Process is also known as a Defunct Process because it is represented in the process table with this name only. Actually, a Zombie process is neither alive nor dead just like an original zombie.
How a Zombie Process is created?
In the Linux environment, we create a Child process using the fork() system call. And the process which calls the fork() system call is called the Parent process.
This parent process has to read the exit status of the child process after its termination using the **SIGCHLD signal and immediately call the wait() system call so that it can delete the entry of the terminated child process from the system’s process table.
This process of deleting the terminated child process’s entry from the process table is called reaping. If the parent process does not make the wait() system call and continue to execute its other tasks then it will not be able to read the exit status of the child process on its termination.
And the entry of the child process will remain there in the process table even after its termination. Hence it becomes a Zombie process. By default, every child process is a Zombie process until its parent process waits to read its exit status and then reaps its entry from the process table.
**SIGCHLD signal: When something interesting happens to the child process like it stops or terminates, a SIGCHLD signal is sent to the parent process of the child process so that it can read the exit status of the child process. By default, the response to this SIGCHLD signal is to ignore it.
C code to create a Zombie process.
#include <stdio.h>
#include <stdlib.h> // for exit()
#include <unistd.h> // for fork(), and sleep()
int main()
{
// Creating a Child Process
int pid = fork();
if (pid > 0) // True for Parent Process
sleep(60);
else if (pid == 0) // True for Child Process
{
printf("Zombie Process Created Successfully!");
exit(0);
}
else // True when Child Process creation fails
printf("Sorry! Child Process cannot be created...");
return 0;
}
Output:
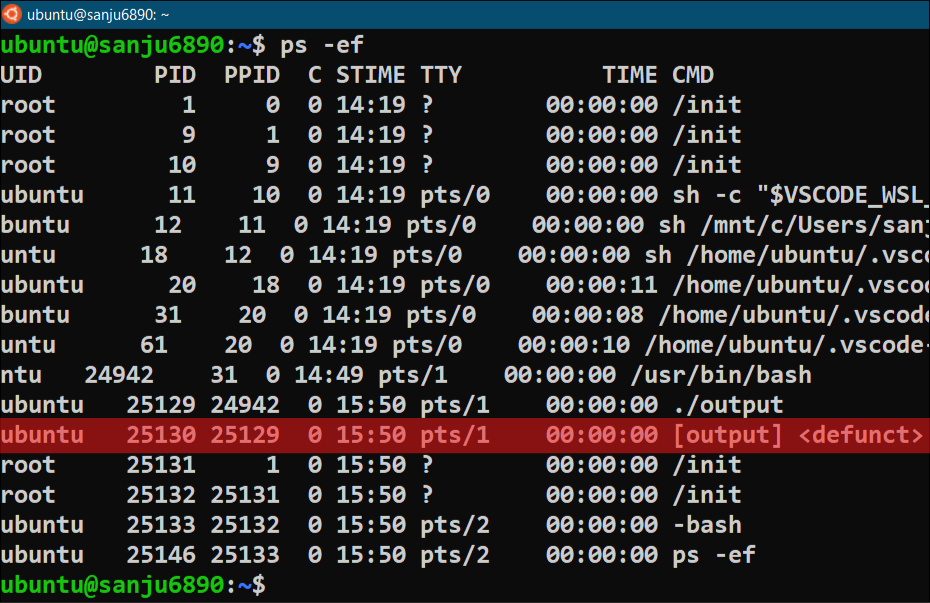
This program has created a Zombie process because the Child process terminates using the exit() system call while the Parent process is sleeping and not waiting for its Child to read its exit status. This Zombie process will be there only for 60 seconds after that the Parent process will be terminated then the Zombie process will be killed automatically. We can see this Zombie process in the system as [output] <defunct> using the following Linux command highlighted with red color.
ubuntu:~$ ps -ef
Output:
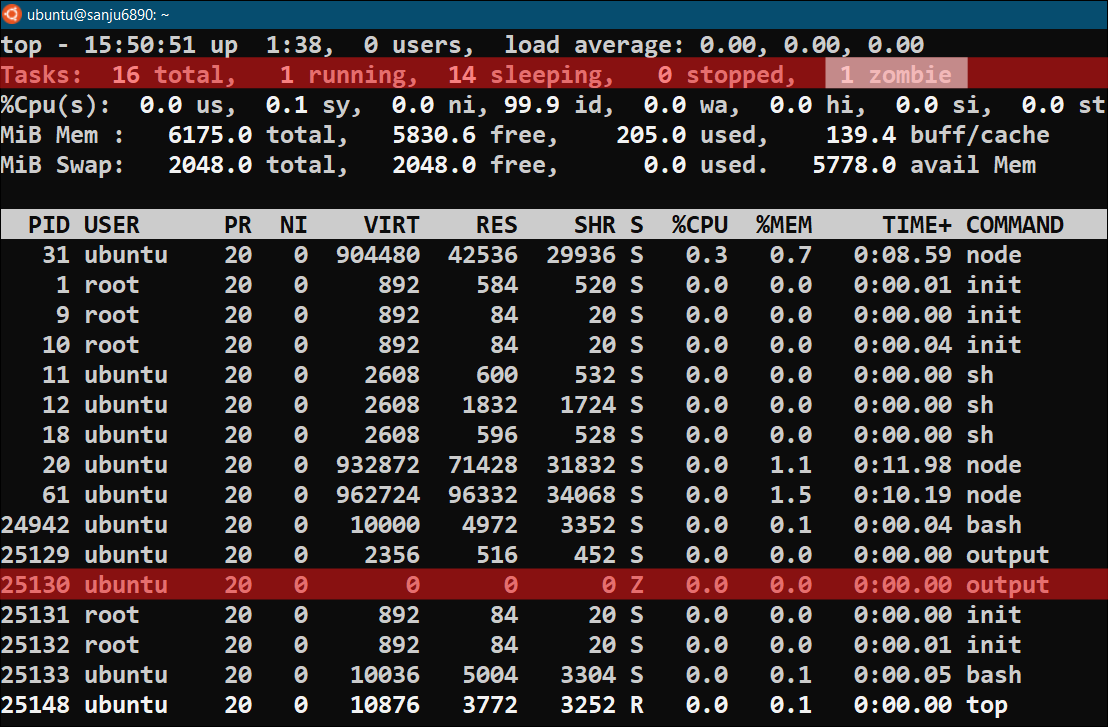
We can also locate the process table entry of this Zombie process using the top command highlighted with red color.
ubuntu:~$ top
Output:
Zombie Process vs Orphan Process
A Zombie process should not be confused with an Orphan process. Because an Orphan process is a process that remains inactive or running state even after the termination of their parent process while a Zombie process remains inactive it just retains its entry in the system’s process table.
An Orphan process can be of two types:
- Intentionally Orphaned Process: An intentionally Orphaned process is an Orphan process that is generated when we have to either start/run an infinite running service or finish a long-running task that does not require any user intervention. These processes run in the background and usually do not require any manual support.
- Unintentionally Orphaned Process: An unintentionally Orphaned process is an Orphan process that is generated when some parent process crashes or terminates leaving its child process in an active or running state. Unlike the Intentionally Orphaned process, these processes can be controlled or avoided by the user using the process group mechanism.
Characteristics of a Zombie Process
Following are some of the characteristics of a Zombie process:
- The exit status of a Zombie process can be read by the parent process catching the SIGCHLD signal using
wait()system call. - As the parent process reads the exit status of a Zombie process then its entry is reaped from the process table.
- After the reaping of a Zombie process from the process table, its PID (process ID) and the process table entry can be reused by some new process in the system.
- If the parent process of a Zombie process gets terminated or finished then the presence of Zombies process’s entry in the process table generates an operating system fault.
- Usually, a Zombie process can be destroyed by sending the SIGCHLD signal to the parent process using the
killcommand. - If a Zombie process cannot be destroyed even by sending the SIGCHLD signal to its Parent process then we can terminate its Parent process to kill the Zombie process.
- As the Zombie’s Parent process is terminated or finished the Zombie process is adopted by the
initprocess and which then kills the Zombie process by catching the SIGCHLD signal and reading its exit status as it keeps making thewait()system call.
Threats associated with Zombie Processes
Although a Zombie process does not use any system resources but retains its entry (PID) in the system’s process table. But the matter of concern is the limited size of the system’s process table. Each active process has a valid entry in the system’s process table.
If anyhow very large number of Zombie processes are created then each Zombie process will occupy a PID and an entry in the system’s process table and there will be no space left in the process table.
In this way, the presence of a large number of Zombie processes in the system can prevent the generation of any new process and the system will go into an inconsistent state just because neither any PID (process ID) is available nor any space in the process table.
Moreover, the presence of a Zombie process generates an operating system fault when their parent processes are not alive.
This is not a matter of concern if there are only a few Zombie processes in the system but can become a serious problem for the system when there are so many Zombie processes in the system.
Maximum number of Zombie Processes in a system
We can find the maximum number of Zombie Processes in a system using the following C program. This C program when executed in the Linux environment it will try to create an infinite number of Child Processes using the fork() system call which has been called inside the while loop.
As we know the fork() system call returns a negative value only when it fails to create a Child Process, so the while loop condition will be true whenever it creates a Child Process successfully and the flag counter inside the while loop will be incremented.
We have also discussed that the size of the process table in the system is limited hence after the creation of a large number of Child Processes (Zombie Processes) there will be no space left in the process table and then the fork() system call will not be able to create any Child Process anymore and hence returns a negative value and this makes the while loop condition false.
In this way, the while loop will stop and the last flag counter value represents the total number of Zombie Processes.
#include<stdio.h>
#include<unistd.h> // for fork()
int main()
{
int flag = 0; // Counter variable
while (fork() > 0)
{
flag++; // Counts the No. of Zombie Processes
printf("%d\n", flag);
}
return 0;
}
Output:
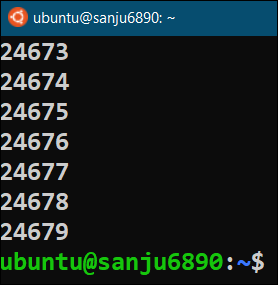
From the output, we can clearly see the maximum number of Zombie Processes that can be created inside the system is 24679.
NOTE: The maximum number of Zombie Processes is the final value of the flag counter which will differ every time you run the above C program depending upon the vacant spaces in the system’s process table.
How to kill a Zombie Process?
If somehow the parent process does not wait for the termination of its child process it will not be able to catch the SIGCHLD signal and hence the exit status of the child process is not read. Then its entry remains in the process table and it becomes a Zombie process.
Then we have to destroy this Zombie process by sending the SIGCHLD signal to the parent process using the kill command in Linux.
As the parent process receives the SIGCHLD signal it destroys the Zombie process by reaping its entry from the process table using the wait() system call. Following is the demonstration of the Linux command to kill the Zombie process manually:
ubuntu:~$ kill -s SIGCHLD <PID>
If anyhow Zombie process cannot be destroyed even by sending the SIGCHLD signal to the parent process then we can terminate its Parent process then
If anyhow Zombie process cannot be destroyed even by sending the SIGCHLD signal to the parent process then we can terminate its Parent process then the Zombie process will be adopted by the init process (PID = 1).
This init process now becomes the new parent of the Zombie process which regularly makes the wait() system call to catch the SIGCHLD signal for reading the exit status of the Zombie process and reaps it from the process table. Following is the Linux command to kill the Parent process:
ubuntu:~$ kill -9 <PID>
NOTE: In both of the above Linux commands just replace the <PID> with the PID (process ID) of the Zombie’s Parent process.
Summing-up
In this tutorial we have learned about the Zombie Process or Defunct Process in Linux, how it is created inside the system, how to locate a Zombie Process in the system, the difference between a Zombie Process and an Orphan Process, various characteristics of a Zombie Process, threats associated with the Zombie Process, how to find the maximum number of Zombie Process in the system, and different ways to kill the Zombie Process in the system.